Process multiple files
Last updated on 2023-03-21 | Edit this page
Estimated time: 22 minutes
Overview
Questions
- How can I check a Snakefile without running the whole workflow?
- How can I create a generic rule that can process multiple files?
- How can I use a python function as part of a rule?
- How do I tell snakemake to create a certain file before running a python function?
Objectives
- Determine a filename plan to download images
- Create a pattern rule to download multiple image files
- Use a python function as a params input
- Setup a checkpoint to ensure a file exists before running a python function.
Snakemake Dry Run
When developing a workflow running the entire workflow after every
change can be time intensive. To help with this snakemake has a
--dry-run flag that will validate the
Snakefile and show what it would do. Try this now:
snakemake -c1 --dry-runCreate a filename plan to save images
When downloading images from the internet it is important to avoid filename clashes. To avoid this problem deciding on a plan for naming the files is important.
The input CSV (multimedia.csv) was downloaded from https://bgnn.tulane.edu/userinterface/. This
multimedia.csv file we are using is only meant to be used
for this workshop and should not be used for any particular research
purpose. To create a real world dataset you could use the https://fishair.org/ website
that replaces the website I used to download this file.
When viewed within RStudio the data looks like this: 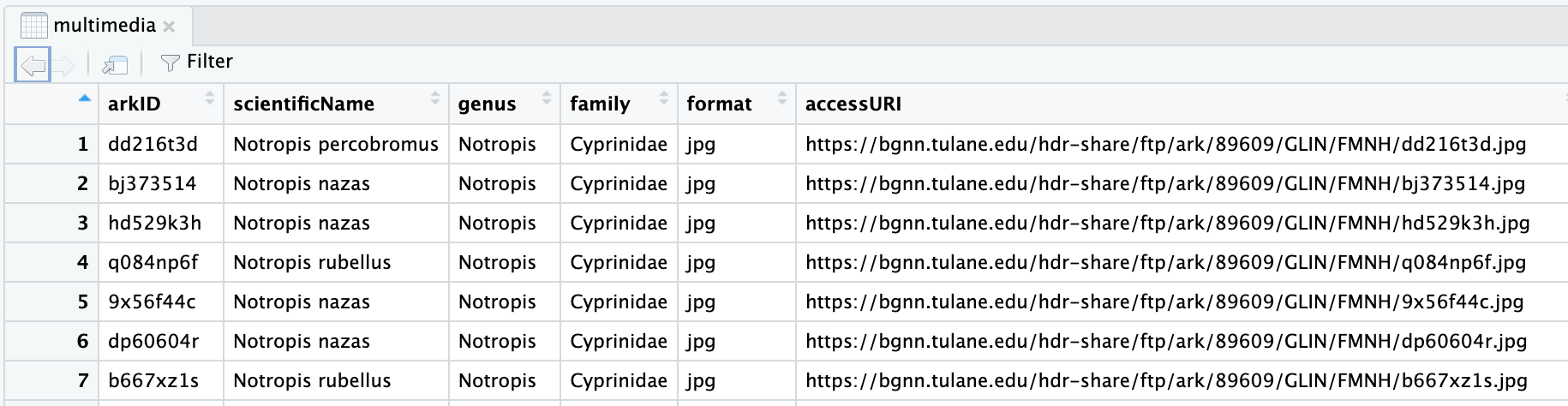
The Tulane multimedia.csv
documentation describes the arkID column as:
Multimedia unique identifier number
arkID seems like a good identifier to use in our image filenames.
For the multimedia row with arkID dd216t3d we will save
the downloaded image as:
Images/dd216t3d.jpgUse wget to download an image
Create a rule that uses a python function
Add a rule to download a single image that uses a python function param:
def get_image_url(wildcards):
base_image_url = "https://bgnn.tulane.edu/hdr-share/ftp/ark/89609/GLIN/FMNH/"
return base_image_url + "dd216t3d.jpg"
rule download_image:
params: url=get_image_url
output: "Images/dd216t3d.jpg"
shell: "wget -O {output} {params.url}"NOTE: Make sure you are using -O and not -o
for the wget argument.
Make the rule generic with a pattern rule
Change this rule to be a pattern rule by adding a wildcard expression in an output filename.
def get_image_url(wildcards):
base_url = "https://bgnn.tulane.edu/hdr-share/ftp/ark/89609/GLIN/FMNH/"
return base_url + wildcards.ark_id + ".jpg"
rule download_image:
params: url=get_image_url
output: "Images/{ark_id}.jpg"
shell: "wget -O {output} {params.url}"Run this rule:
Add python logic to lookup the URL
Add a pandas import to the top of Snakefile:
import pandas as pdChange the get_image_url function to read the CSV file
and add the file as a rule input:
def get_image_url(wildcards):
filename = "multimedia.csv"
df = pd.read_csv(filename)
row = df[df["arkID"] == wildcards.ark_id]
url = row["accessURI"].item()
return url
rule download_image:
params: url=get_image_url
output: "Images/{ark_id}.jpg"
shell: "wget -O {output} {params.url}"Run snakemake:
Updating all rule
Update the all rule adding a function that returns the list of all images that should be created.
def get_image_filenames(wildcards):
filename = config["filter_multimedia"]
df = pd.read_csv(filename)
ark_ids = df["arkID"].tolist()
return expand("Images/{ark_id}.jpg", ark_id=ark_ids)
rule all:
input: get_image_filenamesTest starting from scratch
OUTPUT
Building DAG of jobs...
FileNotFoundError in file /users/PAS2136/jbradley/SnakemakeWorkflow/Snakefile, line 7:
[Errno 2] No such file or directory: 'filter/multimedia.csv'
...Require a file exists before a python function is used
To fix the FileNotFoundError error we need to inform
Snakemake that it needs to wait for the
filter/multimedia.csv file to be created before Snakemake
runs the function.
We need two changes to fix the error:
- Change the filter rule to be a checkpoint instead of a simple rule. This is done by changing the word “rule” to “checkpoint”.
- Add code to the function requesting the output of the
filtercheckpoint.
Update the get_image_filenames function and
filter rule/checkpoint as follows:
def get_image_filenames(wildcards):
filename = checkpoints.filter.get().output[0]
df = pd.read_csv(filename)
ark_ids = df["arkID"].tolist()
return expand("Images/{ark_id}.jpg", ark_id=ark_ids)
...
checkpoint filter:
input:
script="Scripts/FilterImages.R",
fishes=config["reduce_multimedia"]
output: config["filter_multimedia"]
shell: "Rscript {input.script}"Run downloading multiple files
Ensure the downloaded files are jpg
OUTPUT
Images/88624536.jpg: JPEG image data, EXIF standard
Images/9x56f44c.jpg: JPEG image data, EXIF standard
Images/bj373514.jpg: JPEG image data, EXIF standard
Images/dp60604r.jpg: JPEG image data, EXIF standard
Images/hd529k3h.jpg: JPEG image data, EXIF standard
Images/t868dr68.jpg: JPEG image data, EXIF standard