TreeOfLife Datasets
The TreeOfLife datasets are curated collections of images representing a wide range of biological taxa, paired with their corresponding taxonomic labels. These datasets are designed to facilitate the training and evaluation of vision-based knowledge-guided biological foundation models.
TreeOfLife-200M
With nearly 214-million images representing more than 950-thousand taxa across the tree of life, TreeOfLife-200M is the largest and most diverse public ML-ready dataset for computer vision models in biology at release. This dataset combines images and metadata from four core biodiversity data providers: Global Biodiversity Information Facility (GBIF), Encyclopedia of Life (EOL), BIOSCAN-5M, and FathomNet to more than double the number of unique taxa covered by TreeOfLife-10M, adding 50 million more images than BioTrove (and nearly triple the unique taxa).
TreeOfLife-200M also increases image context diversity with museum specimen, camera trap, and citizen science images well-represented. Our rigorous curation process ensures each image has the most specific taxonomic label possible and that the overall dataset provides a well-rounded foundation for training BioCLIP 2 and future biology foundation models.
- Image Count: 213.9 million images
- Unique Taxa: 952,257 unique 7-rank taxa strings
- Image Types: Museum specimen, camera traps, citizen science, drawings (not labeled)
- Sources: Global Biodiversity Information Facility (GBIF), Encyclopedia of Life (EOL), BIOSCAN-5M, FathomNet
- Best for: Large foundation model training.

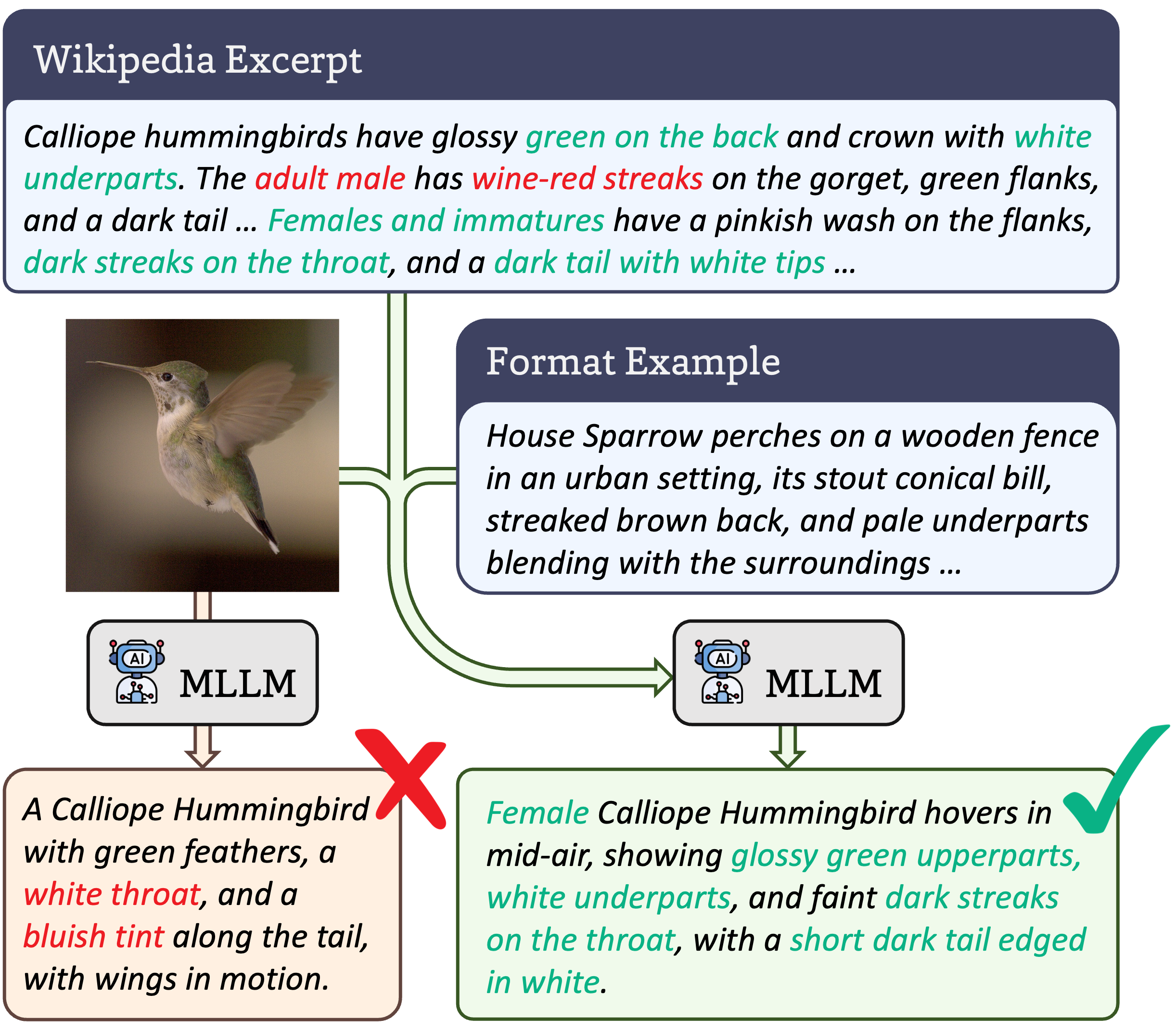
TreeOfLife-10M Captions
A dataset of 10 million generated captions, Wikipedia-derived descriptions and format examples for the TreeOfLife-10M. These captions were generated using InternVL3-38B based on biological contexts that help the model generate more accurate captions. It was used to train BioCAP, a CLIP-based model. This dataset is designed to enhance the training of vision models by providing rich, contextual information about each image included in the original TreeOfLife-10M dataset.
- 10 Million Captions: A diverse set of captions generated for a wide range of biological images.
- Contextual Information: Captions provide rich context to enhance model understanding.
- Training Resource: Specifically designed to improve training for vision models like BioCAP.
TreeOfLife-10M (Original)
The original TreeOfLife dataset presented in "BioCLIP: A Vision Foundation Model for the Tree of Life". With over 10-million images covering 454-thousand taxa in the tree of life, TreeOfLife-10M was the largest-to-date ML-ready dataset of images of biological organisms paired with their associated taxonomic labels.
It expanded on the foundation established by existing high-quality datasets, such as iNat21 and BIOSCAN-1M, by further incorporating newly curated images from the Encyclopedia of Life (eol.org), which supplies most of TreeOfLife-10M’s data diversity. Every image in TreeOfLife-10M is labeled to the most specific taxonomic level possible, as well as higher taxonomic ranks in the tree of life. TreeOfLife-10M was generated for the purpose of training BioCLIP and future biology foundation models.
- Image Count: 10,065,576 images
- Unique Taxa: 454,103 unique 7-rank taxa strings
- Text Types: Common names (black-billed magpie), scientific names (Pica hudsonia), and taxonomic names (Animalia Chordata Aves Passeriformes Corvidae Pica hudsonia)
- Image Types (not labeled): Museum specimen, citizen science, drawings
- Sources: EOL, BIOSCAN-1M, iNat21
- Best for: Smaller foundation model or distilled model training.

