More Research
BioCLIP: A Vision Foundation Model for the Tree of Life
1Samuel Stevens*, 1Jiaman (Lisa) Wu*, 1Matthew J Thompson, 1Elizabeth G Campolongo, 1Chan Hee (Luke) Song, 1David Edward Carlyn, 2Li Dong, 3Wasila M Dahdul, 4Charles Stewart, 1Tanya Berger-Wolf, 1Wei-Lun (Harry) Chao, 1Yu Su,
1The Ohio State University, 2Microsoft Research 3University of California, Irvine 4Rensselaer Polytechnic Institute
*Sam and Lisa are co-first authors and contributed equally to BioCLIP.
stevens.994@osu.edu, su.809@osu.edu

BioCLIP
Images of the natural world are a super-abundant source of biological information. There are many computational methods and tools, particularly computer vision, for extracting information from images. But, existing methods are bespoke models for a specific task and are not adaptable or extendable to new questions, contexts, and datasets.
We develop the first large-scale multimodal model, BioCLIP, for general biology questions on images. We leverage the unique properties of biology as the the application domain for computer vision:
- The abundance and variety of images about plants, animals, and fungi.
- The availability of rich structured biological knowledge.
Demo
Experiments
We evaluate BioCLIP and three baselines (CLIP, OpenCLIP, and an iNat-only model that uses the same procedure as BioCLIP but trained only on iNat21) on a diverse set of biology-related classification tasks. We do zero-shot classification with all models and report accuracy on the validation sets. Bold indicates the best performance for each task.
BioCLIP outperforms both general-domain baselines and our new iNat-only ViT model.
Check out the paper for one-shot and five-shot results.
Scroll to see all results.
| Model | Animals | Plants & Fungi | Rare Species | Mean | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Birds 525 | Plankton | Insects | Insects 2 | PlantNet | Fungi | PlantVillage | Med. Leaf | PlantDoc | |||
| CLIP | 49.9 | 3.2 | 9.1 | 9.8 | 58.5 | 10.2 | 5.4 | 15.9 | 26.1 | 26.6 | 21.4 |
| OpenCLIP | 54.7 | 2.2 | 6.5 | 9.6 | 50.2 | 5.7 | 8.0 | 12.4 | 25.8 | 31.0 | 20.6 |
| BioCLIP | 72.1 | 6.1 | 34.8 | 20.4 | 91.4 | 40.7 | 24.4 | 38.6 | 28.4 | 37.8 | 39.4 |
| iNat21 Only | 56.1 | 2.6 | 30.7 | 11.5 | 88.2 | 43.0 | 18.4 | 25.6 | 20.5 | 19.4 | 31.6 |
Evaluation Examples
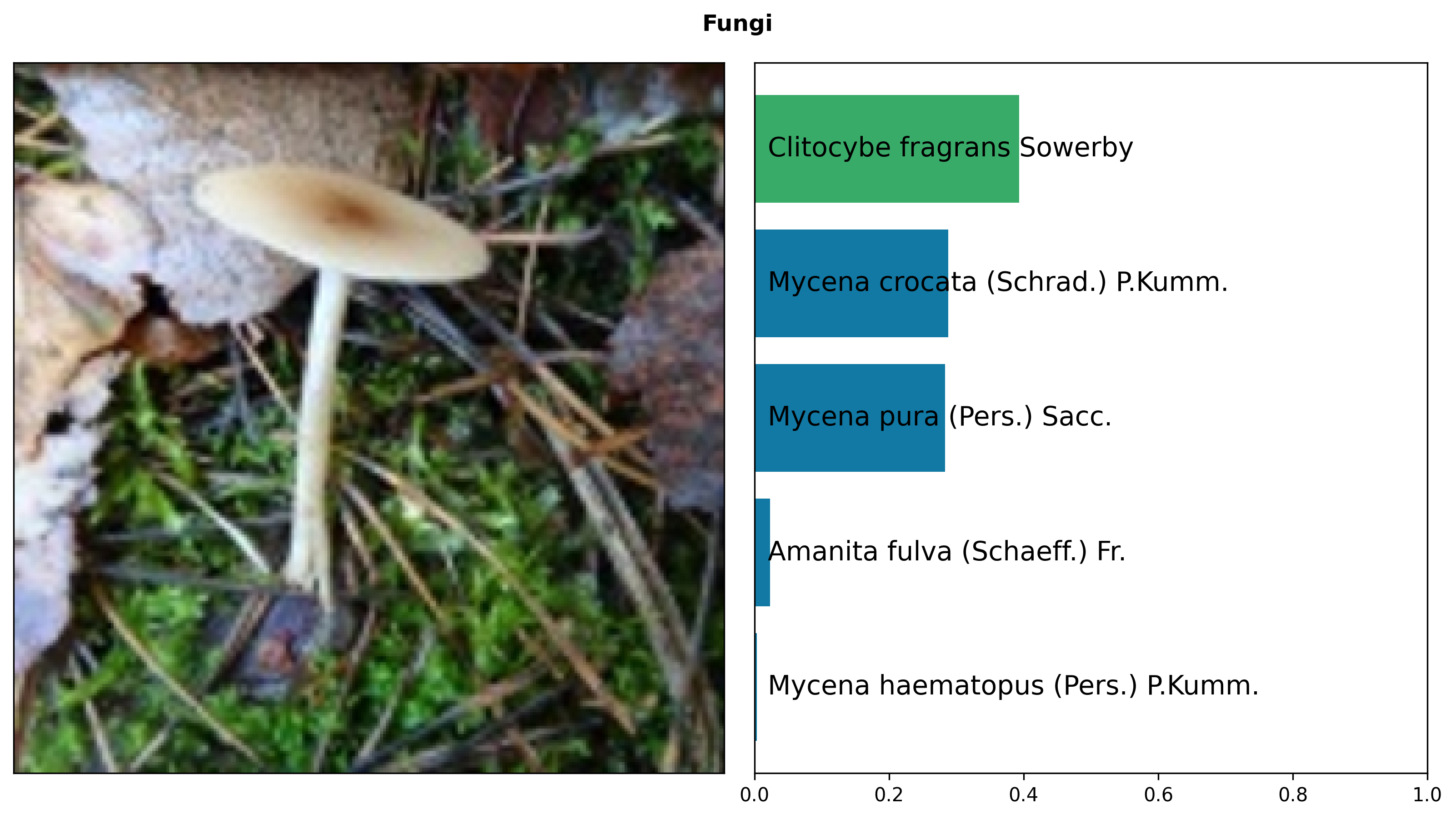

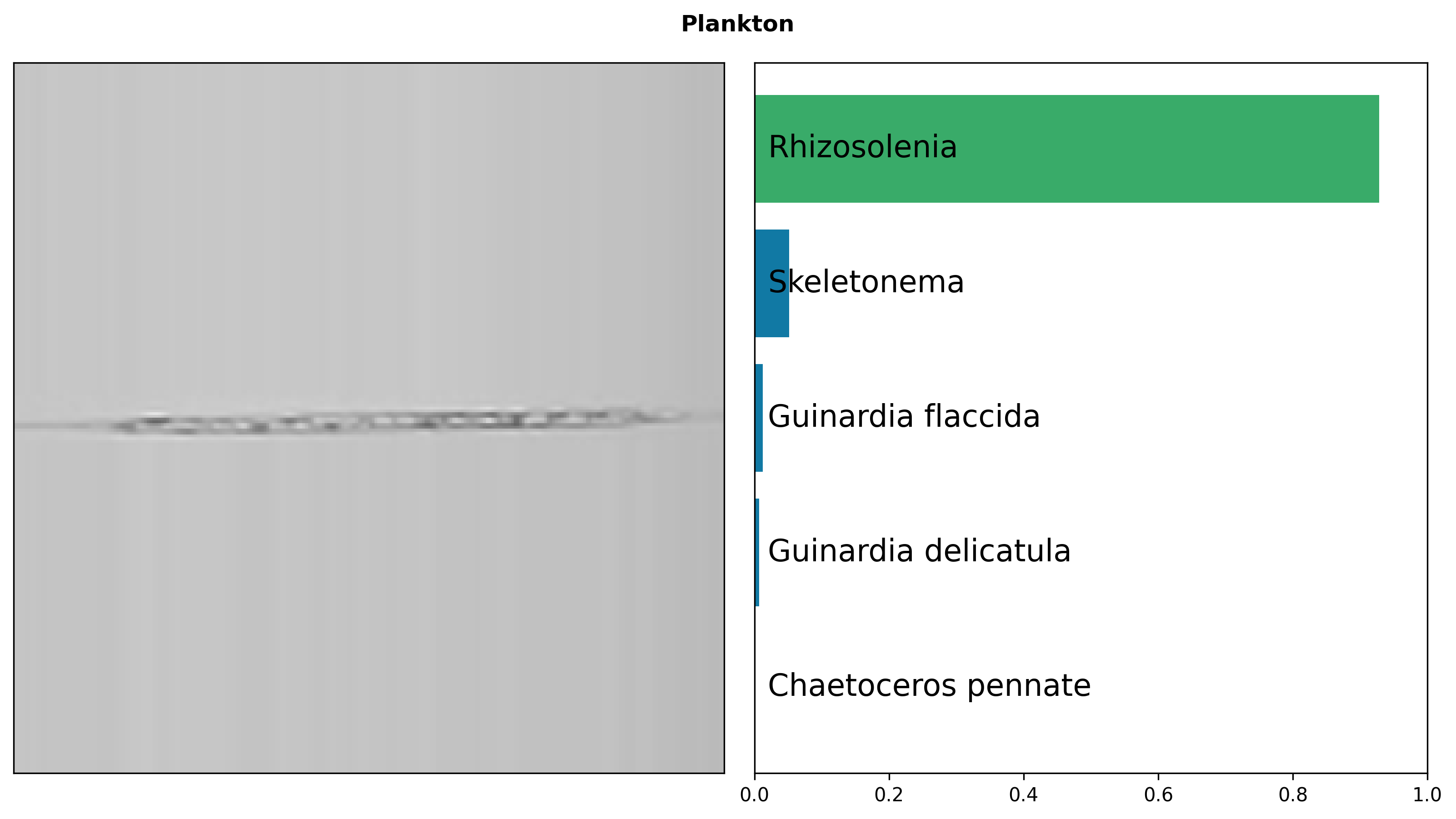
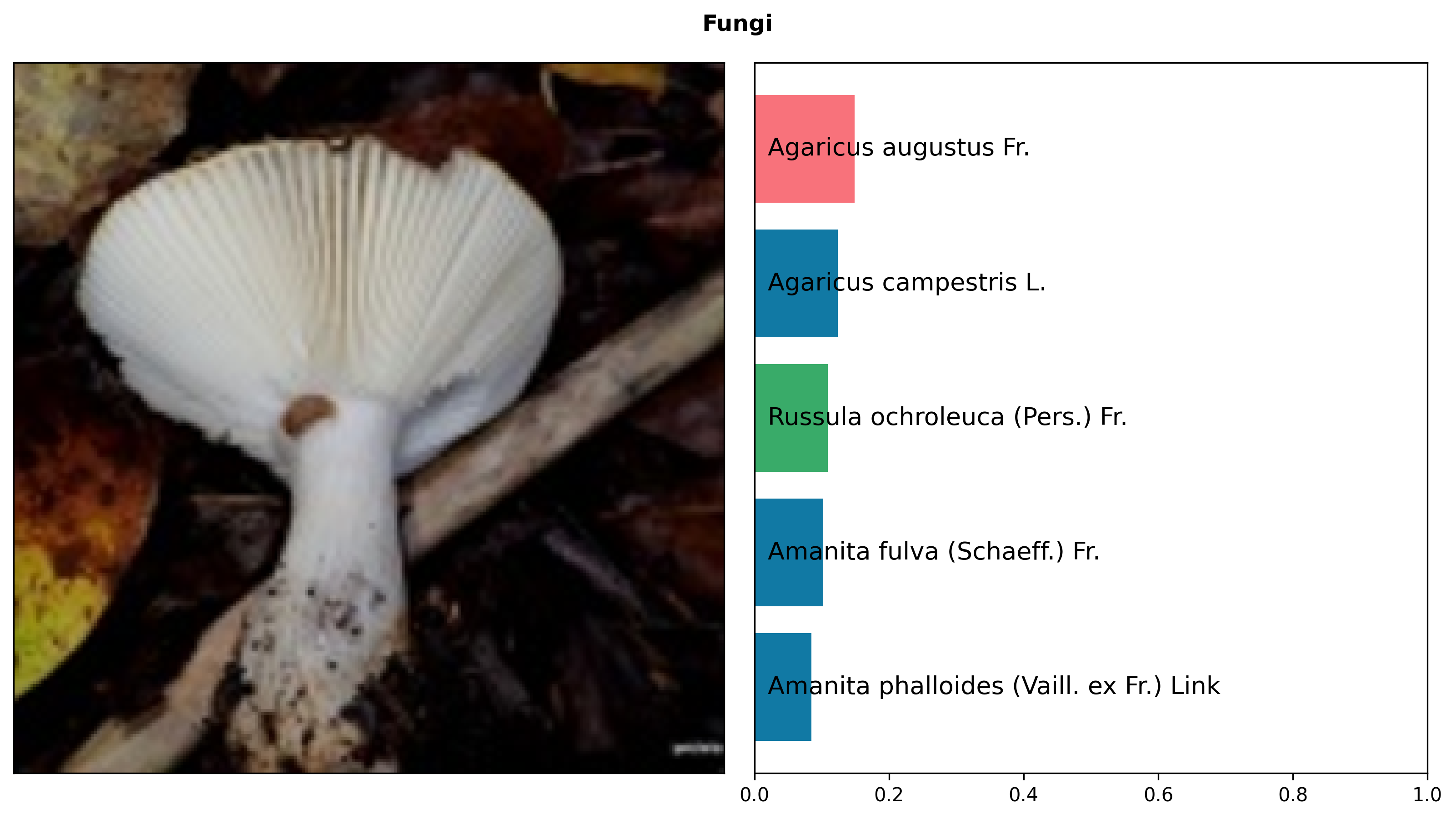
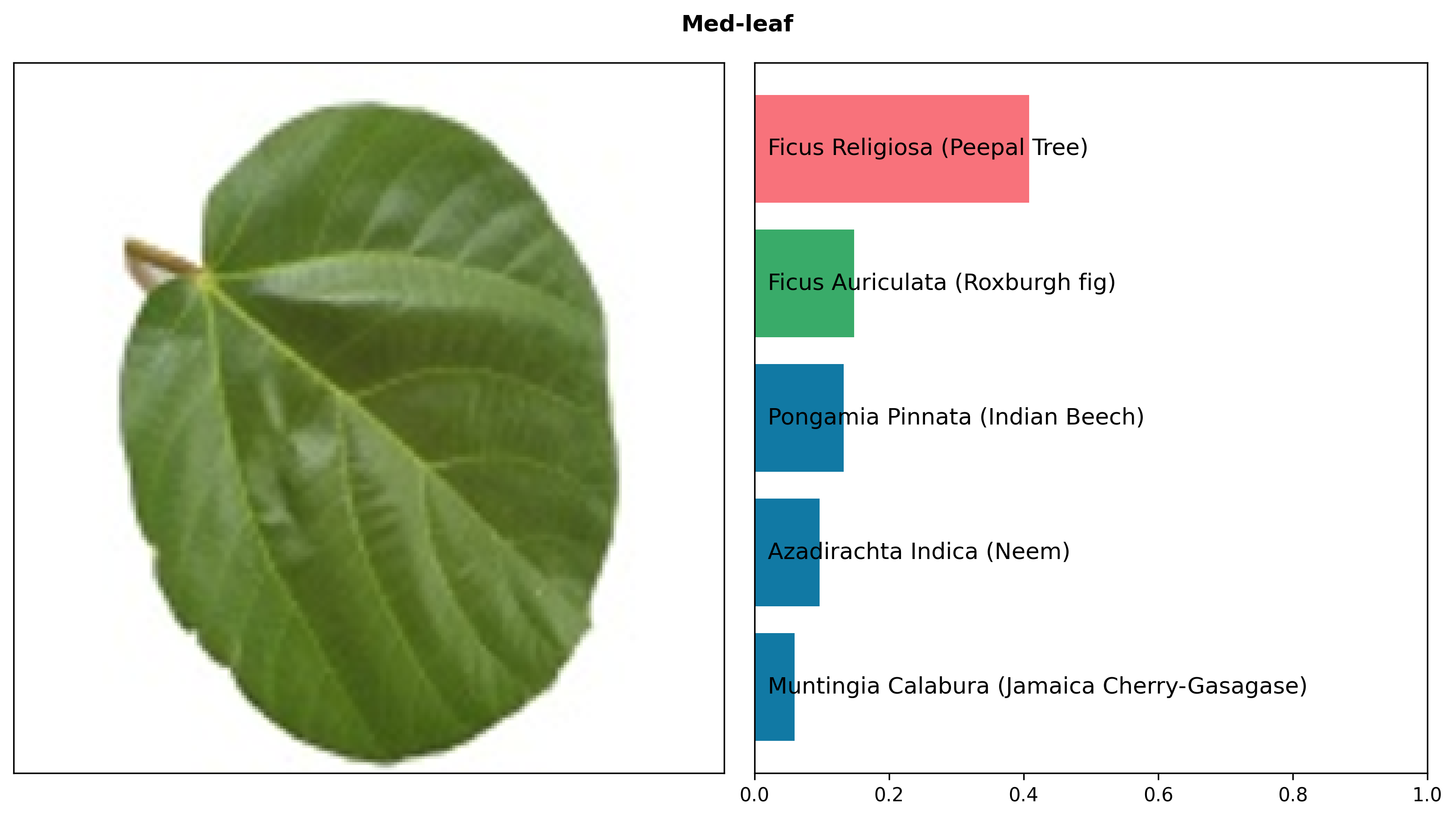
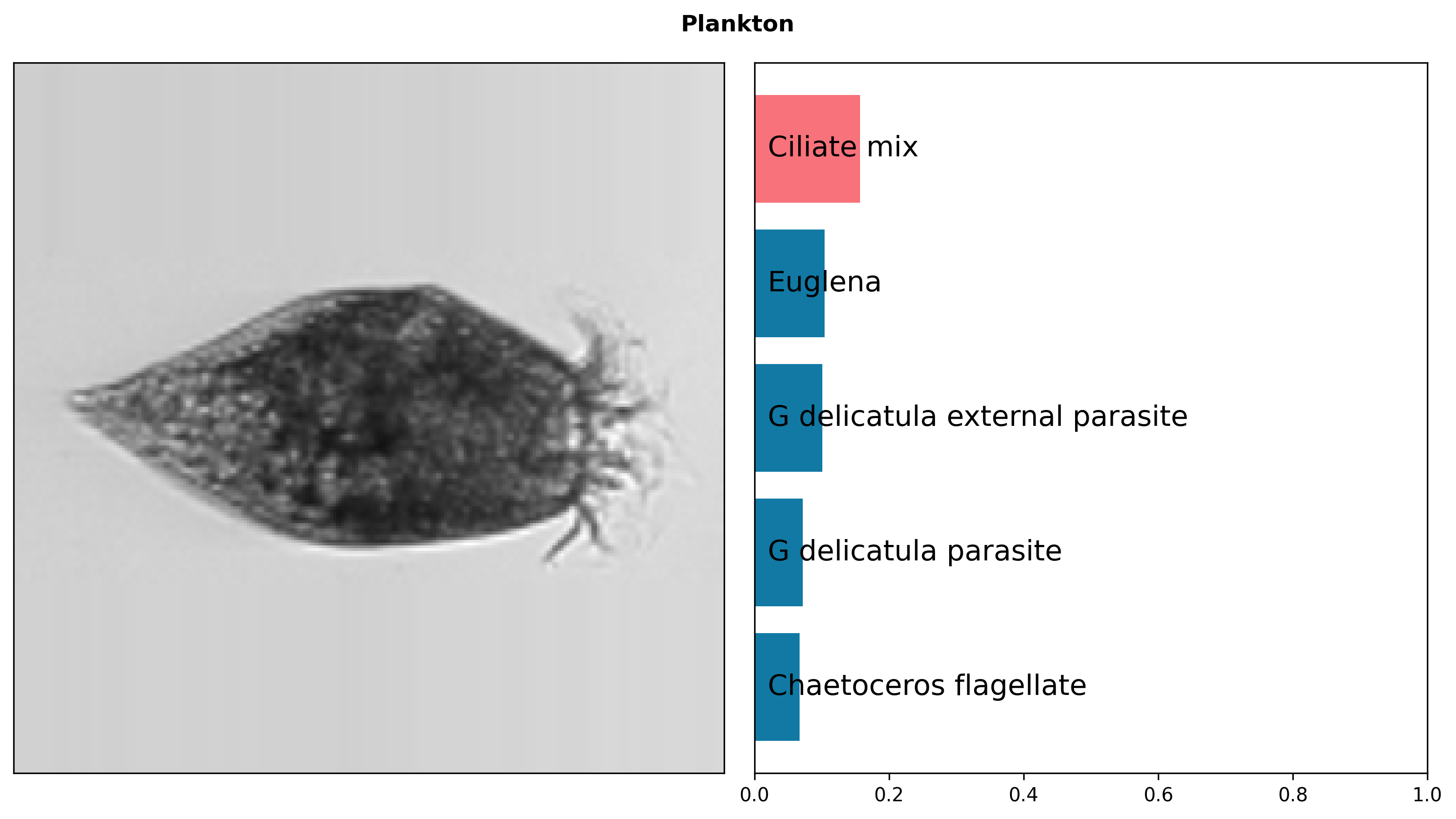
Intrinsic Evaluation
Why does BioCLIP work so well? We conduct an intrinsic evaluation to understand the representations learned by BioCLIP. We visualize BioCLIP and CLIP's representations for the 100K unseen images in the iNat21 validation set, using T-SNE to plot them in two-dimensions, coloring the points based on their class. In the figure below, (B) means BioCLIP and (O) means OpenAI's CLIP.
At higher ranks like phylum, both CLIP and BioCLIP have good separation, but you can see that BioCLIP's representation is more fine-grained and contains a richer clustering structure. At lower ranks, BioCLIP produces far more separable features, while CLIP's features tend to be cluttered and lack a clear structure. This shows that BioCLIP has learned a rich feature representation following the hierarchical structure of the taxonomy, which helps explain its strong generalization across the tree of life.
Dataset
TreeOfLife-10M is the largest and most diverse available dataset of biology images. We combine images from three sources, iNaturalist, BIOSCAN-1M, and Encyclopedia of Life (EOL, accessed 29 July 2023), to create a dataset of 10M images, spanning 450K+ species. We train BioCLIP on TreeOfLife-10M and release the weights for public use.
Reference
Please cite our paper if you use our code, data, model or results.
@inproceedings{stevens2024bioclip,
title = {{B}io{CLIP}: A Vision Foundation Model for the Tree of Life},
author = {Samuel Stevens and Jiaman Wu and Matthew J Thompson and Elizabeth G Campolongo and Chan Hee Song and David Edward Carlyn and Li Dong and Wasila M Dahdul and Charles Stewart and Tanya Berger-Wolf and Wei-Lun Chao and Yu Su},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
pages = {19412-19424}
}
Also consider citing OpenCLIP, iNat21 and BIOSCAN-1M:
@software{ilharco_gabriel_2021_5143773,
author={Ilharco, Gabriel and Wortsman, Mitchell and Wightman, Ross and Gordon, Cade and Carlini, Nicholas and Taori, Rohan and Dave, Achal and Shankar, Vaishaal and Namkoong, Hongseok and Miller, John and Hajishirzi, Hannaneh and Farhadi, Ali and Schmidt, Ludwig},
title={OpenCLIP},
year={2021},
doi={10.5281/zenodo.5143773},
}
@misc{inat2021,
author={Van Horn, Grant and Mac Aodha, Oisin},
title={iNat Challenge 2021 - FGVC8},
publisher={Kaggle},
year={2021},
url={https://kaggle.com/competitions/inaturalist-2021}
}
@inproceedings{gharaee2023step,
author={Gharaee, Z. and Gong, Z. and Pellegrino, N. and Zarubiieva, I. and Haurum, J. B. and Lowe, S. C. and McKeown, J. T. A. and Ho, C. Y. and McLeod, J. and Wei, Y. C. and Agda, J. and Ratnasingham, S. and Steinke, D. and Chang, A. X. and Taylor, G. W. and Fieguth, P.},
title={A Step Towards Worldwide Biodiversity Assessment: The {BIOSCAN-1M} Insect Dataset},
booktitle={Advances in Neural Information Processing Systems ({NeurIPS}) Datasets \& Benchmarks Track},
year={2023},
}
Acknowledgements
The authors would like to thank Josef Uyeda, Jim Balhoff, Dan Rubenstein, Hank Bart, Hilmar Lapp, Sara Beery, and colleagues from the Imageomics Institute and the OSU NLP group for their valuable feedback. We also thank the BIOSCAN-1M team and the iNaturalist team for making their data available and easy to use, and Jennifer Hammack at EOL for her invaluable help in accessing EOL’s images.
This work was supported by the Imageomics Institute, which is funded by the US National Science Foundation's Harnessing the Data Revolution (HDR) program under Award #2118240 (Imageomics: A New Frontier of Biological Information Powered by Knowledge-Guided Machine Learning). Any opinions, findings and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.